Yesterday we wrote our first end to end file tail tool and a consumer for it. It was fatally flawed though in that we could not scale it horizontally and had to run one consumer per log file. This design won’t work for long.
The difficulty lies in the ordering of messages. We saw that NATS supports creating consumer groups and that it load-shares message handling in a random manner between available workers. The problem is if we have more than one worker, there are no longer any ordering guarantees as many workers are concurrently handling messages each processing them at different rates. We’d end up with 1 file having many writers and soon it will be shuffled.
We’re fortunate in that the ordering requirements aren’t necessary for all of the messages, we only really need to order messages from a single host. Host #1 messages can be mixed with host #2, as long as all of the host 1 messages are in the right order. This behaviour is a big plus and lets us solve the problem. We can have 100 workers receiving logs, as long as 1 worker always handles logs from one Producer.
Read on for the solution!
Possible Approaches
We could assume that one worker would be enough to handle all logs. In our example, this might be true. But, let’s assume we’re looking at 100s of thousands of nodes publishing logs.
In the simple case we could subscribe to logs.>, and each host could publish to logs.web1.example.net and we’d save the lines as they come in a single worker. This design won’t work for 100s of thousands of Producers though. Neither would we even be able to do this on one node on the Consumer side; we might need to scale horizontally on the Consumer side to many nodes.
Another approach is to put a key in the data, some other middleware can auto partition based on a data item - but they prescribe your data format. Some have arbitrary headers and allow you to do selectors based on those, they would have been a solid choice here, but NATS has no headers.
So we can dismiss the simple solution, let’s look at an approach that lets us span the message flow across many subjects while maintaining per-publisher order guarantees and that works with NATS.
Partitioning subjects
If, given 4 hosts, we could programmatically determine a number for a host based on something like its name we can calculate the modulus with how many consumers we wish to run to determine in which partition the logs should be placed.
partition = hostNumber % partitionCount
Visually this can be shown as below, 1 consumer can handle many hosts - but 1 host always goes to the same consumer.
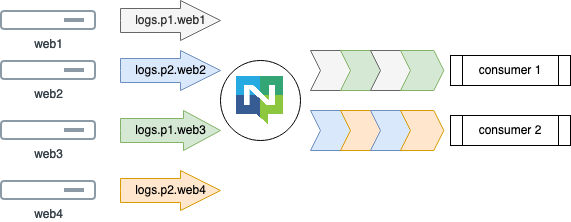
Here’s a table of hosts to partitions to what subject they need to publish their logs.
| Hostname | Partition | Subject |
|---|---|---|
| web1.example.net | 1 | logs.p1.web1.example.net |
| web2.example.net | 2 | logs.p2.web2.example.net |
| web3.example.net | 1 | logs.p1.web3.example.net |
| web4.example.net | 2 | logs.p2.web4.example.net |
The hostname is included in the topic so we can parse this out and perhaps save the logs in /store/logs/web1.example.net/syslog. This way we don’t need processing per line of log and we don’t need to pack it into any serialization format - it’s just bytes.
Using this design, we answer our main problems:
- We can scale the consumers up and spread the load. Both horizontally and vertically.
- We can extract details about the sender and separate the data as required
- We do not do any per-line processing on the contents
The downside here is that we have to pre-agree on how many partitions we wish to support and configure the whole fleet. We can mitigate this by configuring 20 partitions and have 5 consumers where each would consume 4 partitions. This multi partitions per Consumer let us scale horizontally and vertically generously without reconfiguring the fleet.
We’ll add 2 optional environment variables to our configuration:
| Environment | Description | Example |
|---|---|---|
| SHIPPER_PARTITIONS | How many partitions to support, defaults to 0 for none |
10 |
| HOSTNAME | Set this to override the OS hostname, often set by your OS | web1.example.net |
And we will use the hash/fnv package to calculate the hash.
Other than this, the Producer is basically as before, we just interpolate the Partition and Name into the target subject and everything else is unchanged.
Consuming partitions
On the consumer side, it’s a little bit more difficult. Imagine we accept a configuration SHIPPER_READ_PARTITIONS="1,2,3,4,5" that instructs the consumer to listen on logs.p1.>, logs.p2.>, logs.p3.>, logs.p4.> and logs.p5.>.
This approach solves the problem we have of the cost of managing the partitions; we can now also scale the per partition consumption vertically using threads or Go routines in each Consumer.
We make a few small changes to the Consumer, mainly around parsing out hostnames and starting one instance of consumer() per partition.
Shipping logs
We now have some new variables to set. Lets start a Consumer for 5 partitions:
$ SHIPPER_SUBJECT=shipper SHIPPER_OUTPUT=logfile NATS_URL=localhost:4222 \
SHIPPER_READ_PARTITIONS="0,1,2,3,4" SHIPPER_DIRECTORY=/tmp/shipper ./consumer
2020/03/20 12:11:06 Waiting for messages on subject shipper.p0.> @ nats://localhost:4222
2020/03/20 12:11:06 Waiting for messages on subject shipper.p1.> @ nats://localhost:4222
2020/03/20 12:11:06 Waiting for messages on subject shipper.p2.> @ nats://localhost:4222
2020/03/20 12:11:06 Waiting for messages on subject shipper.p3.> @ nats://localhost:4222
2020/03/20 12:11:06 Waiting for messages on subject shipper.p4.> @ nats://localhost:4222
2020/03/20 12:11:11 Creating new log "/tmp/shipper/web1.example.net/logfile-%Y%m%d%H%M"
The meaning of SHIPPER_OUTPUT is now the final file name as stored in ${SHIPPER_DIRECTORY}/${hostname}/${SHIPPER_OUTPUT}. SHIPPER_OUTPUT still has the same pattern handling, still rotates daily, still keeps only a weeks worth.
The Producer is run like here:
$ SHIPPER_FILE=/var/log/system.log SHIPPER_SUBJECT="shipper" \
NATS_URL="localhost:4222" SHIPPER_PARTITIONS=5 ./producer
2020/03/20 12:11:11 Publishing /var/log/system.log to shipper.p4.web1.example.net
Conclusion
At this point we have solved many of our initial problems:
- We can have many, many hosts publishing logs
- We can scale our log consumption horizontally and vertically across many log receivers
- We can have complete redundant clusters of log receiver hosts by simply starting a new cluster
- It’s reasonably easy to configure and operate - however we did lose a bit of the much-valued decoupling by having to pick a partition count ahead of time
Having achieved this much in very little code is quite an achievement, especially as we have only used the most basic pub/sub pattern and nothing else. Mainly, this is down to utilising the features of the middleware and not any cleverness on our part.
As before I’ve put the full code listing on GitHub @ripienaar fshipper tag post5.
The main outstanding problem here is about losing messages. If we even so much as restart one of our consumers we can potentially drop 100s of messages which is no good. This brings us to next week’s topic of JetStream to introduce persistence into the mix.