Last week we built a tool that supported shipping logs over NATS, and consume them on a central host.
We were able to build a horizontally scalable tool that can consume logs from thousands of hosts. What we could not solve was doing so reliably since if we stopped the Consumer, we would drop messages.
I mentioned NATS does not have a persistence store today, and that one called JetStream was in the works. Today I’ll start a few posts looking into JetStream and show how we can leverage it to solve our problems.
Currently, the available NATS Streaming Server sits atop core NATS and provides a level of persistence but the future is JetStream. I want to focus on JetStream system as it’s a much more natural fit into the core NATS world that we are discussing in these posts - our log shipper could have basic persistence without any code changes! Before we get there though let’s look at JetStream.
Today JetStream is in Tech Preview, it does not yet have Clustering or Replication support, so it’s a single node server. Feature-wise though it’s quite complete so it’s good to start prototyping around.
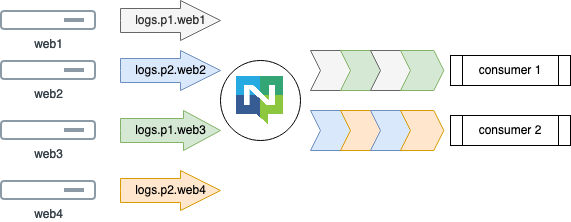
JetStream split the Storage and Consuming of Messages into 2 significant roles:
- Stream - Stores data, consumes NATS subjects and stores messages in a log
- Consumer - Make messages in the stream available to clients, tracks their progress and handles redeliveries
JetStream is a system that you can use to provide persistence to solve several styles of problem: buffering, reliability, work queues, audit trails and more. For our log tailer we’ll mainly provide buffering of messages so that we can handle short periods of the log consumers restarting.
JetStream will be delivered in the same binary as core NATS and will require no additional external services like Consul or ZooKeeper; it’s completely integrated into the NATS Core.
Setting up
Previously we used an official release binary of NATS, for JetStream, today, it’s best to use the preview container.
$ docker run -p 4222:4222 -v /tmp/jetstream:/tmp/jetstream synadia/jsm:latest server
[1] 2020/03/26 09:04:06.318438 [INF] Starting nats-server version 2.2.0-beta.7
[1] 2020/03/26 09:04:06.318507 [INF] Git commit [060a86a]
[1] 2020/03/26 09:04:06.318521 [INF] Starting JetStream
[1] 2020/03/26 09:04:06.319024 [INF] ----------- JETSTREAM (Beta) -----------
[1] 2020/03/26 09:04:06.319036 [INF] Max Memory: 5.73 GB
[1] 2020/03/26 09:04:06.319040 [INF] Max Storage: 1.00 TB
[1] 2020/03/26 09:04:06.319071 [INF] Store Directory: "/tmp/jetstream"
[1] 2020/03/26 09:04:06.319085 [INF] ----------------------------------------
[1] 2020/03/26 09:04:06.319233 [INF] Recovering JetStream state for account "$G"
[1] 2020/03/26 09:04:06.319348 [WRN] Missing Stream metafile for "/tmp/jetstream/$G/streams/ORDERS/meta.inf"
[1] 2020/03/26 09:04:06.319353 [INF] JetStream state for account "$G" recovered
[1] 2020/03/26 09:04:06.319555 [INF] Listening for client connections on 0.0.0.0:4222
[1] 2020/03/26 09:04:06.319560 [INF] Server id is ND2PIK7U55APIPCWOBDE62ZQT5GLKXADC2RIWST26NTKOO4X5IQDCELQ
[1] 2020/03/26 09:04:06.319562 [INF] Server is ready
This command uses the preview build and runs nats-server -js which starts a standard NATS Server with the JetStream feature enabled. It listens on 4222 so be sure to stop the nats-server from previous posts.
Creating a Stream
Streams store messages in an appending log, just like our log files. Streams have many options for setting how big we want the Stream to grow like how old messages can be, how many messages we store, or how big the store can be. We’ll keep one day’s worth of logs in the examples below which gives us plenty of time to do maintenance and other activities requiring downtime.
A reminder that our log tailers publish on subjects like logs.p<partition>.<hostname> so we are going to need a stream that consumes wildcards.
We have some choices in configuring the Stream: we could create a stream for all partitions, a stream per partition or dynamically add per-partition streams as needed using Stream Templates. We’ll keep it simple with one Stream for all the logs.
The nats utility also manages JetStream; you can see in the video below it has a friendly interactive mode.
You can also use it non interactively:
$ nats str add LOGS --subjects "logs.>" \
--storage file \
--retention limits \
--max-msgs=-1 \
--max-bytes=-1 \
--max-age 1d \
--max-msg-size=-1
For full deep dive into what all this means I suggest the Tech Preview Docs
Since the Stream is using standard NATS subjects, we can use our producer from previous posts unmodified to put messages in the Stream:
Note we have set up no log consumers at all, so this data is now effectively being buffered here and kept for up to 24 hours.
Consuming from a Stream
Consumers consume messages from the Stream, each Stream can have many Consumers - even thousands if you wish. Consumers can either be Push mode or Pull mode. As we’ve been using the Pub/Sub method so far in our code, let’s focus on Push mode Consumers first.
Below we set up a basic Consumer and show that logs are in the Stream.
Above we created 2 consumers each with their own view over the logs. Messages are sent to the consumer with no acknowledgements or retries.
Retries and Acknowledgements
So far, having just used JetStream as a buffer with no Acks or Retries, we’ve kind of only solved our problem halfway. We can go away and come back later to find logs, but there aren’t many guarantees that every single log is delivered. Let’s look at how we can make this reliable.
On the publishing side, we can not be sure our logline is received successfully at the moment; JetStream, though, can acknowledge receiving the message:
$ nats request logs.p1.my.host "sample log line"
11:00:56 Received on [_INBOX.hUhAF0B1hlKG0eS5HtJUrm.itQwb40A]: '+OK'
Here we use the Request/Response pattern to publish to logs.p1.my.host with a fake logline, and the server responds with +OK after persisting the message. So if we desire delivery guarantee of logs, we can code it to support that in the shipper. I imagine this would not be for all logs though; you might not care for every single logline. But if you wanted to use this for shipping an audit log, you could add an option to the shipper to send a specific log in acknowledged mode and retry lines when they fail.
On the Consumer side, we have a few options:
- Read each message from the push mode subject and acknowledge them.
- Read messages and acknowledge every 100, or every 30 seconds. The server assumes all previous ones were received.
- Pull a message and acknowledge it
- Pull 100 messages and acknowledge the last, implying all pulled ones were acknowledged
In general, I tend to avoid Acknowledgements on push mode messages because they are retried by just resending them when your consumer might not be ready. Duplicates can happen, and in general, it’s just a bit awkward if you expect a high number of messages. It can work well if you do your own re-ordering of messages or your processing is idempotent so that duplicates and order do not matter.
Let’s look at Pull Consumers and Acknowledgements a bit:
In the above video, I set up a Consumer that’s in Pull mode and has acknowledgements and retries. We show acknowledged messages do not come back and that you can set an upper limit on delivery retries.
Conclusion
Today we looked at the basics of JetStream, but we only scratched the surface. Have a look at the Tech Preview Docs for the full picture.
As it relates to our log shipper, we saw that without any modification to the Producer, we could add persistence to the logs so we can survive restarting of Consumers. We saw that in order to get our Consumers to work reliably we’ll need some modifications to their code, which is what the next post is all about.