Back in 2011, I wrote a series of posts on Common Messaging Patterns Using Stomp; these posts were very popular, I figured it’s time for a bit of refresh focusing on NATS - the Middleware Choria uses as it’s messaging transport.
Today there are 2 prevailing architectures in Microservices based infrastructure - HTTP based and Middleware based Microservices. I’ll do a quick overview of the two patterns highlighting some of the pros and cons here; first, we look at the more familiar HTTP based and then move to Middleware based. In follow-up posts, we’ll explore the Middleware communication patterns in detail and show some code.
Note though the context here is not to say one is better than the other or to convince you to pick a particular style, I am also not exhaustively comparing the systems - that would be impossible to do well.
Today the prevailing architecture of choice is HTTP based, and it’s demonstrably a very good and very scalable choice. I want to focus on using Middleware to achieve similar outcomes and what other problems they can solve and how - the aim is to share information and not to start a product/architecture comparison debate.
Series Index
- Series introduction
- Description of the major messaging patterns supported by NATS
- Running NATS Server and exploring patterns from the CLI
- Creating a basic log distribution tool
- Adding scalability to the log distribution tool
- Introducing JetStream
- Interacting with the JetStream API
- Adjusting the log distribution tool for JetStream
- Reliable delivery and Acknowledgement Patterns
HTTP Based
In a Serverless and Microservices architecture, we rely on API Gateways and Service Meshes quite a lot. The primary purpose for these is to provide routing from client to server. All communication to services gets routed via this layer.
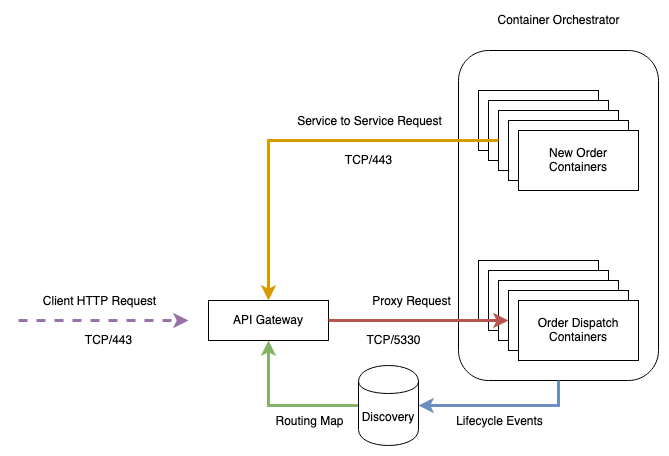
Here we have a (very) simplistic view of an HTTP based service in a modern Microservice architecture.
Container Orchestrators like Kubernetes hosts and schedule Containers. Container Scheduling tasks create events that a Discovery database, like Consul, consume to build a route map. These maps contain lists of containers belonging to a service and what - dynamically chosen - ports are listening on those containers. The API Gateway uses this information to create a routing table used to map incoming requests to backend microservice. Proxy requests to the Microservice get initiated based on the route map entries.
Typically these API Gateways direct not just your external traffic but also your internal traffic. Here should the Order Create service need to communicate to the Order Dispatch service it would do so via the Gateway.
Some Service Mesh products are distributed services running as a side-cars to each instance of the service. Communication between services goes via these side-cars meaning for everything you run, you end up running one or more side-cars and offloading TLS and more onto them, so the “API Gateway” is more a virtual construct in that case made up of 10s, 100s or 1000s of components that can consume vast amounts of resources.
The Service Mesh takes care of addressing, rolling upgrades, metrics, tracing and more. Typically this is a big multi-component service that scales horizontally.
Things get more complicated when you want to do Events to multiple recipients or implement observer Patterns; you have to make webhook registrations and make many HTTP requests or build long-running HTTP poll systems which start to resemble a Broker in many ways. HTTP/2 is efficient and reuses long-running connections. Still, there is a marked cost of creating and tearing down HTTPS connections.
There are many infrastructure components to manage here. You’re constrained in your choices because the Service Mesh layer integrates with your Container Orchestrator, and this is a complicated service made up of many moving parts to manage. HTTP however is a widely adopted protocol supported by almost any language. You don’t need a Service Mesh in development; they are more or less invisible to you, make HTTP calls as you’ve always done.
Middleware Based
The alternative is to use messaging between your services, here rather than per-request connections that each need to be authenticated, authorized etc., we create long-running connections to a central entity - that may or may not live in your Container Orchestrator - and use a naming convention for finding and accessing services. This single long-running (optionally) TLS connection is used for bi-directional traffic and can carry many subjects of data concurrently.
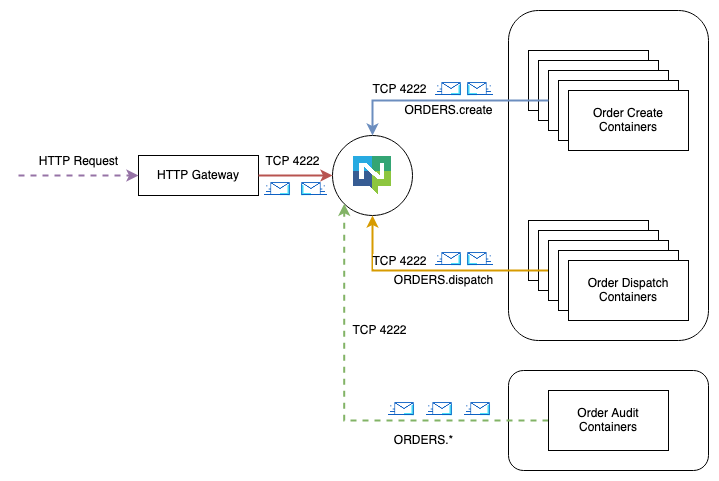
The Middleware is purpose-built software that routes messages between named endpoints like ORDERS.created called Subjects and often supports wildcards like ORDERS.*. The analogue to an HTTP request that expects a response is to set up a short-lived subscription called in INBOX and send a message to ORDERS.create asking it to send its reply to _INBOX.xxxx which is a unique subject. This communication happens over the single long-running TCP connection.
NATS supports multi-tenancy, where each service (each uniquely coloured line) is a separate account that gets authenticated once. The accounts agree on policies of what traffic can flow between them. If the Order Create service needs to communicate with the Order Dispatch service, this has to be agreed by both and only this traffic can flow.
There is no service Discovery service, no Container Orchestrator integration; you’re not coupled to a Container Orchestrator or even to a single cluster. Here the Order Audit service may or may not be in the same cluster, and it shows how a listen-only service can subscribe to all related traffic for an audit log - assuming other accounts agree to this.
Scaling any of the services is a matter of starting a new instance; nothing else has to be aware that this new instance started. The Middleware delivers traffic to the new instance as needed; new instances can run in the same cluster or remote clusters. Geographic intra-cluster failover happens automatically. However, since the Middleware does not integrate tightly with your platform, it does not get involved with things like phased upgrades of your services.
This architecture is message orientated and supports 3 main patterns: a specific instance receiving a message in a 1:1 manner, round-robin load sharing within a service or 1:n broadcasts to all services who have interest in the data. This architecture is inherently well suited to evented systems and observer patterns - but as we’ll see also a good fit for request/reply patterns along with the same design as HTTP requests.
Unlike HTTP based systems, you need to use special client libraries and a potentially unfamiliar coding pattern, and you might take a longer time to get started. You need a Middleware Broker in development; they are however often very lightweight and easy to run - NATS is just ./nats-server in a single binary. The Middleware layer can be hosted in your Container Orchestrator or elsewhere; it does not know or care where your services run and have no integration points into the platform. You’re free to mix and match technology and architectures as long as they support the protocol needed.
I pointed out that the Service Meshes can be very resource hungry and made of many pieces - so can MoM, NATS though is very lightweight, single binary and scales well with few resources.
Conclusion
Both of these designs have definite pros and cons; I’ve tried to highlight some of those in the preceding sections.
I don’t want to say which is better; I think right this instant HTTP based designs are the winner, in terms of adoption, for Microservices architecture as they hold the mind share.
Middleware based is a different way of doing things, and your development teams might need to learn a bit more - but in my opinion in the bigger picture you’re not going to spend less time learning weird new things with either of these systems and running an extensive network of either is hard work.
It makes sense to explore and learn and decide if either of these is fit for your needs. In the following posts, I hope to show how to achieve some of the same outcomes as HTTP based service architecture but also how we can use the MoM to our advantage to solve some problems that are hard with HTTP.
This wraps up the first post in our series; I’ll link the rest here as they become available.