Yesterday, in our previous post, we did a light compare between HTTP and Middleware based architectures for Microservices. Today we’ll start focusing on Middleware based architectures and show some detail about the why’s and the patterns available to developers.
Why Middleware Based
The Middleware is a form of Transport, rather than addresses you think in named channels and the endpoints within that channel decides how they consume the messages, 1:1, 1:n or randomly-selected 1:n.
The goal is to promote an architecture that is scalable, easy to manage and easy to operate. These goals are achieved by:
- Promoting application design that breaks complex applications into simple single-function building blocks that’s easy to develop, test and scale
- Application building blocks are not tightly coupled and can scale independently of other building blocks
- The middleware layer implementation is transparent to the application – network topologies, routing, ACLs etc. can change without application code change
- The brokers provide a lot of the patterns you need for scaling – load balancing, queuing, persistence, eventual consistency, failover, etc.
- Mature brokers are designed to be scalable and highly available – very complex problems that you do not want to attempt to solve on your own
- Fewer moving parts, less coupled to infrastructure layers and scalable across multiple clusters
There are many other reasons, but for me, these are the big-ticket items – especially the 2nd one.
Modern Middleware comes in many flavours; they excel at different patterns. NATS, at this moment, does not have a strong persistence play while others are persistent all the time. These differences represent trade-offs to consider when picking a solution.
Generally, they are fast, scalable, lightweight and reliable but do not think they are magic. There are always limits, and you need to invest upfront in monitoring and observability at every level.
Your choice of Middleware come with trade-offs, some dedicate an OS thread per subscription or subject meaning you are limited in how many subjects you can create. It pays to spend time learning and experimenting.
NATS supports a cluster of clusters - called superclusters - these are made for connecting clusters over a long distance. They do not conquer the speed of light, and you’ll still be subject to latencies on many levels.
If you wish to design a complex application that relies heavily on your Middleware for HA and scaling you should expect to spend as much time learning, tuning, monitoring, trending and recovering from crashes as you might with your DBMS, Web Server or any other big complex component of your system.
However I’ve run vast NATS networks in support of Choria hosting many 100s of thousands of connections with millions of subscribers and traffic exceeding 20MB/sec, it’s one of the most reliable pieces of software in my stack.
Roles
Generally, there are two roles in a message orientated design. Some software consumes messages and is called Consumers while others produce a message and so are called Producers. The lines blur a bit in the case of services since the service consumes a message and then produces a reply message holding the result of the request.
Major Patterns
There are several message patterns you can choose when designing your application that we’ll look at below. The types available depend on your role, understanding these are key to your success in building on middleware.
Where possible the behaviour between the Producer and the Consumer is decoupled in a way that the code for all components would not need to change when topologies in one component change, this same decoupling is present in the security and observability features.
Streams or Pub/Sub
Pub/Sub messages aka a Stream in NATS Core terminology is a unidirectional flow of messages out of a Producer to any number of Consumers. Every Consumer who subscribes to the subject gets a copy of the messages; typically, there are no replies from the recipients back to the Producer.
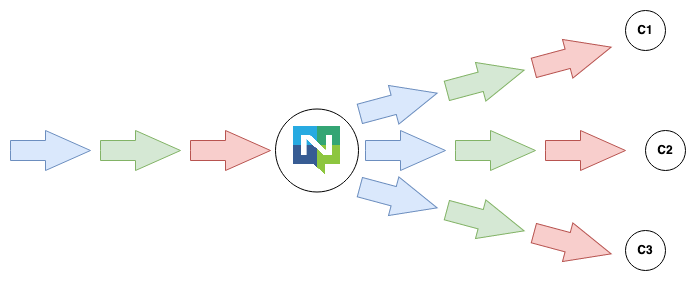
A key point here is that the Producer does not know how these messages are consumed. The Producer decides to publish messages on a subject like STOCK.NASDAQ.AAPL and 1 or many subscribers get the messages.
This pattern is suitable when implementing the observer pattern, any consumer who is interested in the data can subscribe to it and get a copy of all the messages - each subscriber gets all the messages.
Horizontally scaled Streams
The previous pattern had every consumer receiving every message, this is fine for many kinds of use cases, but if you wanted to process these messages in a scalable manner, you might want to run your service over multiple instances and have each message consumed by one instance in the cluster of services.
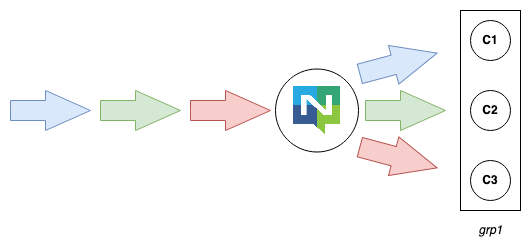
Here we demonstrate that a group of Consumers agree on a group name - grp1 - and use that when subscribing to the subject. The NATS Server delivers the messages to the consumers in a random manner, each receiving one of the messages.
It’s important to note that the choice to receive the messages in a Pub/Sub manner or a Queue Group is entirely up to the subscribers. You can have many groups with each group having this behaviour and you can even have a mix of Consumer Groups and Pub/Sub consumers, the Pub/Sub ones receive all messages while the grouped ones have their messages distributed. The Producer does not need to change to facilitate this.
Requests expecting a Reply
The final pattern allows one to implement an interactive service. The Client becomes a Consumer on a temporary subject like _INBOX.XXX and Produce a message to the Service on WEATHER.SERVICE. The Produced message has a reply-to set asking the Service to send the result to _INBOX.XXX. The Service parses the request and sends the reply to the Client. The Client unsubscribes from the INBOX.
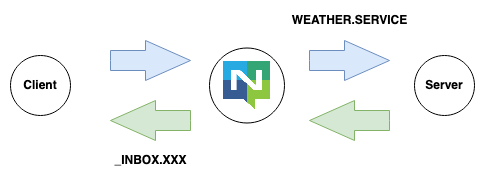
Here the Client has to know this is the pattern to use and has to do some setup.
This pattern can combine with the preceding two:
- Multiple Weather Service instances can listen on the WEATHER.SERVICE and all respond, the Client uses the first result received. This multi-publish seems wasteful but can provide natural resilience to a service
- Multiple Weather Service instances can listen on WEATHER.SERVICE in a group, spreading the workload horizontally across a pool of workers without providing such a strong resilience guarantee
- Multiple Weather Service instances can listen on WEATHER.SERVICES in multiple groups, in all groups, a single worker responds, the Client uses the first result received. A combination of the first 2 patterns that scales horizontally and provides resilience
- Weather Services instances in any of the above configurations can listen in multiple clusters in a super-cluster. The nearest serve the request providing free and automatic geographic failover across regional boundaries
This pattern is exactly like an HTTP request to a backend service if the backend does not respond in either scenario the client retries or gives up receiving an answer.
A specialisation on this is the case where you publish a Request to a subject that has many Servers, each Server replies and instead of using just the first one the Client consumes all the messages and aggregates them. This pattern is precisely how a Choria discovery message works.
Persistence and Guarantees
NATS is an at-most-once based system, this means the message might be lost, but if a delivery attempt is made, it gets delivered at most once to any one Consumer. Ordering between a single Producer and Consumer is guaranteed. The at-most-once implies that a message can get lost, this is because NATS does not have a persistence layer if the Consumer is not there at the time a message is Produced the message is not stored and not delivered later.
Currently in Tech Preview is a feature called JetStream that will support at-least-once delivery for messages. This means persistence can be enabled for a particular subject and Consumers can receive their messages later. We’ll take a quick look at JetStream a bit later.
NATS does not support exactly-once message semantics.
Security
The above sections all showed 2 main actors involved in message flows. NATS has extensive security controls, in the most advanced setup, each Microservice or each Producer and each Consumer would have different users belonging to different accounts.
Messages within the same account flow, by default, unhindered however given multiple accounts when a specific Client wishes to access the Weather Service they would need to have an agreement between themselves and the Weather Service that this flow is allowed. A similar security pattern applies to unidirectional Pub/Sub flows.
Managing the security between the various roles isn’t done in your code, it’s a property set in the JWT used to authenticate to NATS which is a welcome decoupling.
Observability
In the case of the Request/Reply Service pattern, when using multiple accounts, a service can be set to have observability traces published about the flows of requests and responses.
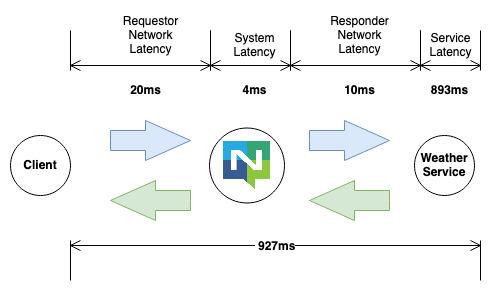
Here four latency dimensions are tracked, with times in ns, latency samples are published to NATS and look like this:
{
"app": "weather_service",
"start": "2009-11-10T23:00:00Z",
"svc": 893000000,
"nats": {
"req": 20000000,
"resp": 10000000,
"sys": 4000000
},
"total": 927000000
}
Consuming and graphing these can provide valuable insight into the flows and performance of your services.
Conclusion
This brings us to the end of Part 2 in our series, we’ve seen the significant patterns of message flows NATS supports and had a quick tour of security, observability and more. Tomorrow we’ll interact with NATS using its CLI tools and explore these patterns interactively.