In the past we’ve had a project called Stream Replicator that was used to copy data between independent NATS Streaming Server instances. I’ve needed an updated version of this, see the full text for links to a brand new ground-up rewrite of this tool that support JetStream.
At a basic level the system simply takes all data in one Stream found in a cluster and copies it all to another stream in, potentially, another cluster. We maintain order and, it’s a long-running process so the 2 streams are kept up to date.
The streams can have different configurations - different storage types, different retention periods, different replication factors and more, even different subject spaces.
That’s the easy part, the harder part is where we meet some Choria specific needs. Choria Servers support sending chunky packets of metadata containing lots of metrics and metadata about the nodes. In a single Data Center sending this data frequently all is fine, but when you are operating 100s of thousands of nodes no central metadata store can realistically keep up with the demand this place on it. At a medium scale this can equal to many MB/sec.
The Choria Stream Replicator supports inspecting the data streams, tracking individual senders and sampling data out of the stream - sending data for any given node once per hour, while the node itself publishes every 5 minutes.
Using this method one can construct tree structures - city-level data centers feeding regional aggregators which in turn feed a large central data store. 5 minute freshness at the city level, 30 minutes at the region and hourly at the central.
Further, while replicating and sampling data the Stream Replicator will track nodes and send small advisories about new nodes, nodes not recently seen and nodes that are deemed retired. By ingesting these advisories regionally or centrally a real time view of global node availability can be built without the cost of actually processing node level data.
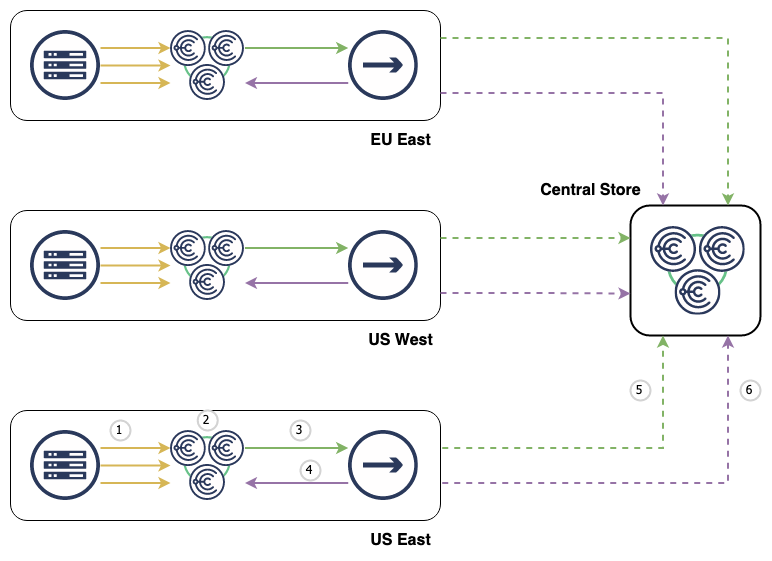
Given the above diagram, the Replicator supports:
- Choria Fleet Nodes publish their metadata every 300 seconds
- Choria Data Adapters place the data in the
CHORIA_REGISTRATIONstream with per-sender identifying information - Stream Replicator reads all messages in the
CHORIA_REGISTRATIONStream - Sampling is applied and advisories are sent to the
CHORIA_REGISTRATION_ADVISORIESstream about node movements and health - Sampled Fleet Node metadata is replicated to central into the
CHORIA_REGISTRATIONstream - All advisories are replicated to central into the
CHORIA_REGISTRATION_ADVISORIESstream without sampling
I gave a talk detailing this pattern at Cfgmgmt Camp 2019 that might explain the concept further.
This is quite niche stuff, though the Replicator would be generically useful, it’s tailored to the needs of our Large Scale Choria Deploy reference architecture.
Today I released Version 0.5.0 that’s a ground-up rewrite of this software that support JetStream.
Documentation can be found on the project Wiki, RPMs and Docker containers are available.