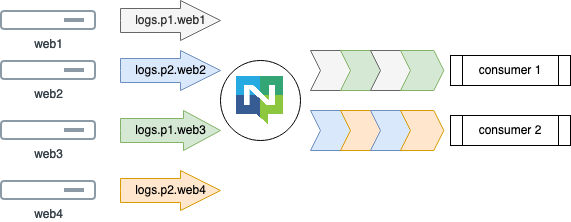
In our previous posts, we did a thorough introduction to messaging patterns and why you might want to use them, today let’s get our hands dirty by setting up a NATS Server and using it to demonstrate these patterns.
Setting up
Grab one of the zip archives from the NATS Server Releases page, inside you’ll find nats-server, it’s easy to run:
$ ./nats-server -D
[26002] 2020/03/17 15:30:25.104115 [INF] Starting nats-server version 2.2.0-beta
[26002] 2020/03/17 15:30:25.104238 [DBG] Go build version go1.13.6
[26002] 2020/03/17 15:30:25.104247 [INF] Git commit [not set]
[26002] 2020/03/17 15:30:25.104631 [INF] Listening for client connections on 0.0.0.0:4222
[26002] 2020/03/17 15:30:25.104644 [INF] Server id is NA3J5WPQW4ELF6AJZW5G74KAFFUPQWRM5HMQJ5TBGRBH5RWL6ED4WAEL
[26002] 2020/03/17 15:30:25.104651 [INF] Server is ready
[26002] 2020/03/17 15:30:25.104671 [DBG] Get non local IPs for "0.0.0.0"
[26002] 2020/03/17 15:30:25.105421 [DBG] ip=192.168.88.41
The -D tells it to log verbosely, at this point you’ll see you have port 4222 open on 0.0.0.0.
Also grab a copy of the nats CLI and place this in your path, this can be found in the JetStream Releases page, you can quickly test the connection:
$ nats rtt
nats://localhost:4222:
nats://127.0.0.1:4222: 251.289µs
nats://[::1]:4222: 415.944µs
Above shows all you need to have a NATS Server running in development and production use is not much more complex, to be honest, once it’s running this can happily serve over 50,000 Choria nodes depending on your hardware (a $40 Linode would do)
[Read More]