Playbooks
Choria has many agents and actions, in isolation they can be useful but they are best used in combinations forming part of a larger Orchestration. Thus far people had to write Ruby code interacting with the RPC API to do that - there has been no higher level scripting system.
Choria is hardly ever stand alone in any infrastructure, there are always other sources of truth, other APIs etc. Imagine you might want node lists from Consul or etcd, or some YAML file. Imagine you want to notify webhooks, or run arbitrary shell scripts, or call to systems like Slack for notification or speak to Razor to provision nodes or Terraform for EC2 resources - all of these would be tasks or data stores you’d wish to incorporate in such a script.
Choria Playbooks is a system that lets you write sets of tasks, inputs, discovery rules and so forth to solve complex infrastructure orchestration problems. Playbooks are written using the familiar Puppet Language and can be documented using the standard Puppet Strings utility.
While Playbooks are Choria Agent centered they support integrating a range of 3rd party components into your flows.
Typical Use Case
By way of an example here is typical use case I have in mind:
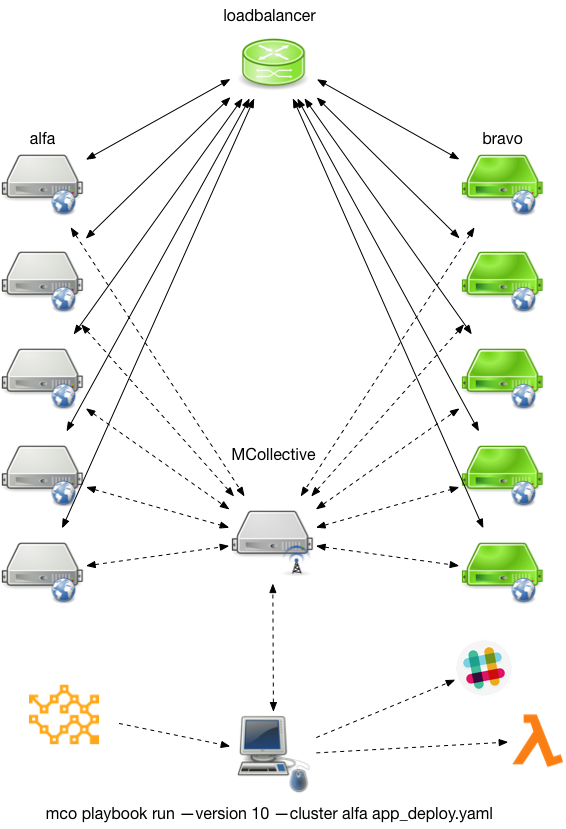
Here we want a playbook that can upgrade one of the 2 tiers - alfa or bravo - by using a number of Choria Agents such as haproxy, nrpe, puppet, appmgr (used to manage our internal app) etc.
We want to do:
- Discover the haproxy using PuppetDB
- Discover the webservers grouped by alfa and bravo clusters to do blue-green deployment of the tiers. Based on input from the user selecting the tier. Using PuppetDB.
- Validate versions of agents and test connectivity
- Upgrade the specific web tier using:
- Disable puppet on the webservers
- Wait for any running puppet runs to stop
- Disable the nodes on a particular haproxy backend
- Upgrade the apps on the servers using appmgr#upgrade to the input revision (fictional agent)
- Do up to 10 NRPE checks post upgrade with 30 seconds between checks to ensure the load average is GREEN, you’d use a better check here something app specific
- Enable the nodes in haproxy once NRPE checks pass
- Fetch and display the status of the deployed app - like what version is there now
- Enable Puppet
- Write a particular templated log line
Should any step above fail:
- Call a webhook on AWS Lambda
- Tell the ops room on slack
- Run a whole other playbook called deploy_failure_handler with the same parameters
Should the upgrade steps pass:
- Call a webhook on AWS Lambda
- Tell the ops room on slack
Status
The playbook feature is working, several data stores are supported and it’s functional. Further feedback from users are sought to drive the future of these.
A large refactor of the code is due after the removal of the legacy YAML based playbooks. The aim is to simplify the implementation greatly and perhaps even make it extendable by way of other Puppet modules so adding new behaviors into the Playbook system will be easy for anyone after the transition period.